响应谱分析
当地震作用于结构物时,结构物产生的动态反应可以用响应谱来描述。响应谱分析是一种用来评估结构在地震作用下的动态响应的分析方法。在进行响应谱分析时,首先需要确定结构物的质量、刚度和阻尼等参数,然后将这些参数代入结构的动力方程中,通过计算得到结构在不同频率下的加速度、速度或位移的最大响应值,这些最大响应值就是所谓的响应谱。
响应谱分析可以帮助工程师评估结构在地震作用下的强度和韧度,从而指导结构的设计和加固,以提高结构的地震抗震性能。响应谱分析也是地震工程领域中常用的一种分析手段,对于重要的工程结构,如核电站、高层建筑和大型桥梁等,进行响应谱分析是非常重要的。
使用CAE365网站,我们可以通过下面的几个步骤轻松开启响应谱仿真
进入CAE365网站
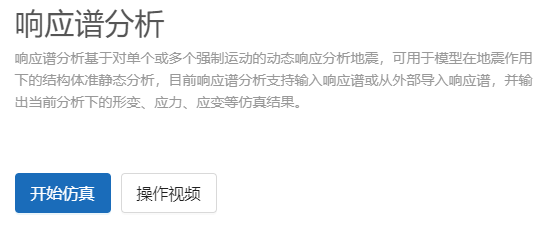
在页面下方模块栏中选择结构仿真-响应谱分析,点击开始仿真按钮,开始仿真:
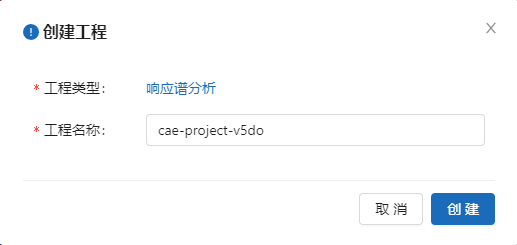
在弹出的创建工程窗口中输入工程名:
输入工程名称后,点击创建,进入响应谱仿真界面:
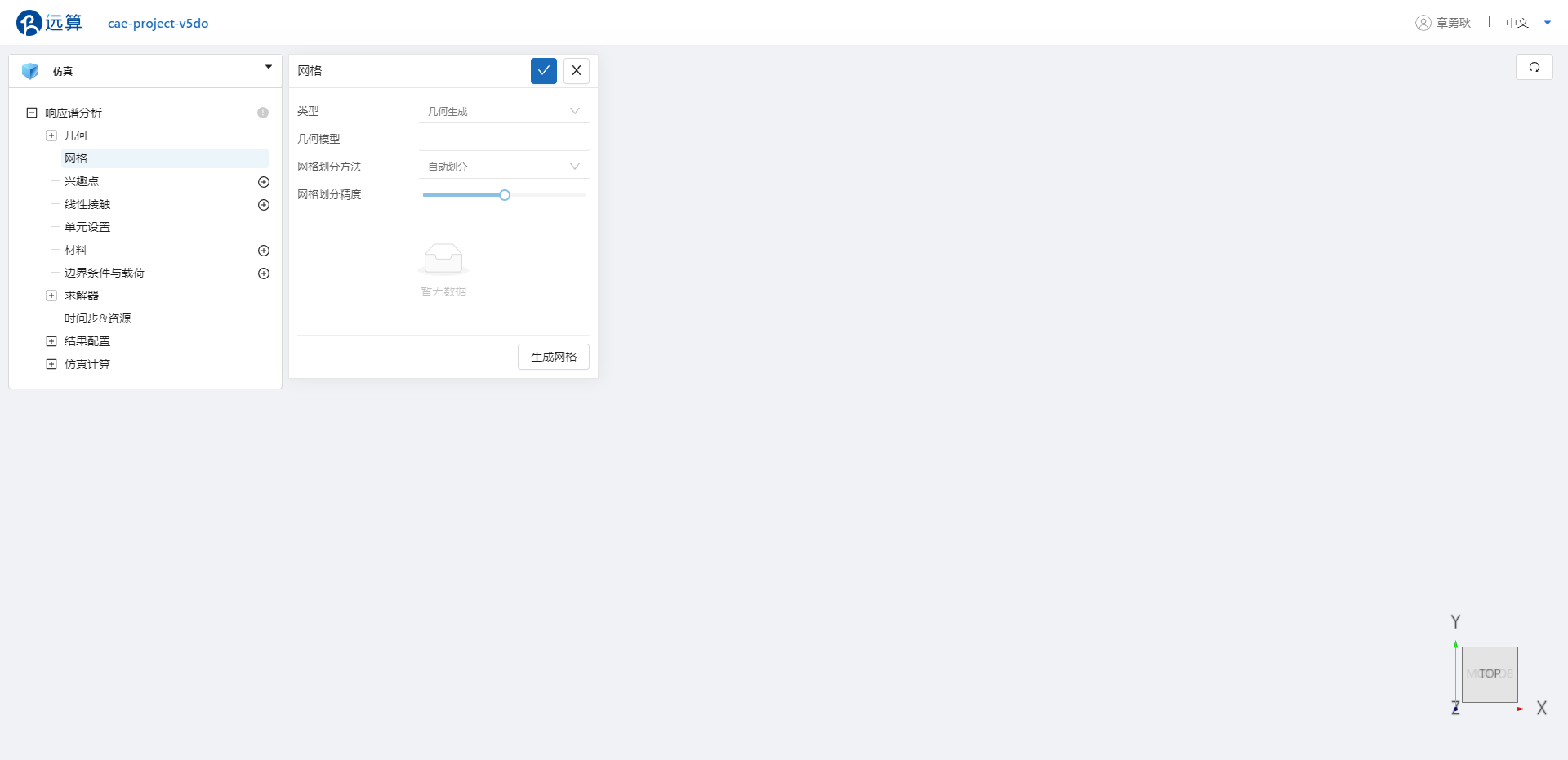
响应谱仿真模块树如图所示:
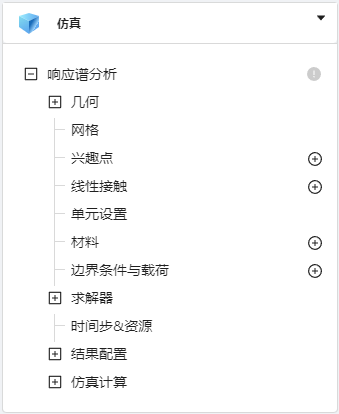
1. 产品手册
1.1 几何导入
用户可以在这里上传几何模型,模型格式建议为iges、step、brep、xao且大小不超过200M。
1.1.1 几何分组
用户可以在几何模型中创建点、线、面、体的分组。
1.2 网格导入
用户可通过点击网格,导入本地网格,格式建议为,med、inp、cdb、cgns且大小不超过200M。用户需预先把所需的载荷组与约束组定义完整,否则在后续的仿真分析中不能选择未定义组的点、线、面和体。 同时可以在此选项按照平台内置算法划分网格。
1.3 兴趣点设置
在此选项卡中,用户可定义兴趣点,以便在后续的结果展示中可直接查看兴趣点的计算结果。
1.4 线性接触
在模型建立时没有进行融合操作的结构都需要对其进行接触设置。线性接触指两个物体表面之间没有相对滑移,并且满足胡克定律(Hooke's law),即力与位移成正比。
在此选项卡中,用户可选择绑定、相对滑动两种连接方法,并自定义接触位置和位置容差。
1.5 单元设置
在此选项卡中,可手动或自动选择设置三维完全积分单元或者三维缩减积分单元类型,以及网格阶数为一阶或者二阶。
1.6 材料设置
在此选项卡中,用户可选择大部分常用材料(如钢、铁、铝、玻璃、橡胶、陶瓷等金属和非金属材料),材料包含基础的力学特征,如本构行为、密度、泊松比、杨氏模量等。
1.7 边界条件与载荷
在此选项卡中,用户可选择边界类型和施加位置,边界类型包括:固定支撑、弹性支撑和位移约束。
1.8 求解器
在此选项卡中,用户可自定义设置求解选项,响应谱分析包含前置模态分析设置和响应谱分析设置。
1.8.1 前置模态分析设置
在此选项卡中,用户可选择不同的计算方法,选择不同的迭代方法和收敛准则以及特征值求解方法
1.8.2 响应谱分析设置
在此选项卡中,用户可设置响应谱激励和模态合成方法。
1.9 时间步&资源
在此选项卡中,用户可设置计算的核数以及最大计算时间。
1.10 结果配置
在此选项卡中,用户可根据需要选择特定的输出结果,包括位移(总位移、周期模态总位移、刚体模态总位移)、应力(总应力、冯米塞斯应力、周期模态总应力、刚体模态总应力),结果以云图方式展示,还有兴趣点的折线图结果。
1.11 仿真计算
在此选项卡用户可以提交计算,并在此处查阅相关的云图结果和兴趣点的折线图结果。
2. 教程案例
3. 设置项详解
3.1 几何
用户可从本地上传几何文件,上传后选项卡会展示几何外形,显示顶点数量、边线数量、环线数量和面数量等。
- 几何分组:上传几何文件后,用户需对几何进行分组,以便在后续的仿真分析中选择所需的点、线和面。不分组自动画网格功能不能使用!
3.2 网格
用户可从本地上传网格文件,上传后选项卡会展示网格外形,显示单元数量、节点数量、边线数量和面数量等。上传网格文件前,用户需提前对模型进行分组,以便在后续的仿真分析中选择所需的点、线和面。
用户也可将上传的几何文件在此处划分网格,生成.med文件。
- 类型:在此处选择用于计算的网格来源
- 几何生成:将上传的几何文件剖分
- 上传网格:直接导入外部网格模型
- 几何模型:当类型处选择“几何生成”时,此处默认的是导入几何的文件名。
- 网格划分方法:此处选择划分网格的算法。
- 自动划分:平台自动生成四面体网格,只能调节网格密度。
- 手动划分:可以调节网格的单元最大最小尺寸以及网格密度
- 网格划分精度:控制网格密度的滑块,0代表网格最粗糙,4代表网格最精细。
- 单元最大尺寸:手动划分时,用户可以自定义单元的最大长度。
- 单元最小尺寸:手动划分时,用户可以自定义单元的最小长度。
3.3 兴趣点
用户可在模型上选择兴趣点,以便在后续的结果展示中以列表形式查看兴趣点的结果。
- 点:通过三个坐标定义一个点。
- 球:通过三个坐标和半径定义一个球。
- 圆柱:可以设置半径、参考点坐标、坐标原点坐标。
- 笛卡尔盒子:可以设置最小值和最大值坐标。
3.4 线性接触
- 连接方法
- 绑定:通过约束条件将两个物体或结构件紧密连接在一起,使其在仿真分析过程中保持稳定的相对位置和运动关系。
- 相对滑动:许两个接触面在接触表面相切的平面上有位移,但不允许沿接触面法线方向有位移。
- 位置容差:从属面距主从面最近的距离,该选项会改变接触的区域大小。
- 启用
- 不启用
- 容差:启用位置容差后可在此处设置容差数值,用户自定义的浮点数。
- 主接触面位置:在选择主接触面时,必须选择体单元类型!!!
- 从接触面位置:从接触面选择另一个接触面。
3.5 单元设置
当单元设置为“自动”时,默认选择二阶、三维完全积分单元;当设置为“手动”时,用户可选择三维完全积分单元或三维缩减积分单元;当单元设置为“手动”时,用户可选择一阶或者二阶网格;
- 单元设置:
- 自动
- 手动
- 单元类型
- 三维完全积分单元
- 三维缩减积分单元
- 网格阶数
- 一阶
- 二阶
3.6 材料
材料选项卡中用户可定义全局的材料性能,包括材料本构行为(默认线弹性),杨氏模量、泊松比、密度,单位也可根据需要随时改变。
点击材料的加号按钮,用户可选择内置的不同材料,各项材料力学基本属性都已默认填写,同时可根据用户需要赋予所属模型网格。
3.7 边界条件
边界条件定义了结构的支撑情况和结构与外部环境的相互作用,点击边界条件与载荷旁的加号按钮可选择不同的边界类型:
- 固定支撑:用户可在该选项卡中选择对应的体、面、线、点施加6个自由度方向的固定约束。
- 弹性支撑
- 边界类型:弹性支撑
- 弹簧刚度
- 各向同性:各个方向的刚度一致,一个变量即可表示弹簧刚度。
- 各向异性:三个方向的刚度不一定一致,需要3个变量表示弹簧的刚度。
- 刚度定义
- 整体模型:定义的刚度值将应用于面的所有节点;
- 分布模型:刚度将分布到应用刚度的面区域;
- K
- x:用户自定义数值,表示X方向的刚度大小。
- y:用户自定义数值,表示Y方向的刚度大小。
- z:用户自定义数值,表示Z方向的刚度大小。
- 施加位置:选取边界所作用的位置。
- 位移约束:用户可在该选项卡中选择对应的体、面、线、点施加3个平动自由度的位移,用户可通过勾选对应方向的选择框来自由选择所需方向的位移条件,数值可通过直接输入值、表格输入、函数输入三种方式输入。
3.8 求解器
求解器面板包含前置模态分析设置和响应谱分析设置。
3.8.1 前置模态分析设置
该选项卡包含控制有限元模态分析方程求解的一些设置,包括算法选择、残差和阈值类型、模态求解方法、求解模态阶数、最大迭代次数等。求解计算方法包含:MUMPS,LDLT,Multifrontal三种方法
- MUMPS
- 奇异性监测精度:设置矩阵奇异性评估的数值精度,如果设置负值则关闭监测
- 矩阵类型
- 自动检测
- 非对称矩阵
- 对称不定矩阵
- 矩阵优化内存分配率:用于数据透视操作估计量之上保留的内存比例设定
- 是否进行预处理:用户可选择是否启用矩阵的预分析用以优化计算
- 矩阵重新编号方法:矩阵优化算法,对仿真计算的内存消耗有巨大影响:
- AMD:使用近似最小度数方法
- SCOTCH:是一个强大的重新编号工具,适用于大多数场景,是MUMPS的标准选项
- AMF:使用近似最小填充方法
- PORD:是MUMPS中包含的重新编号工具
- QAMD:是自动检测准密集矩阵的AMD变体。
- Automatic: MUMPS自动选择重新编号的方法
- 内存管理优先级:允许选择RAM与磁盘的使用情况
- 自动:允许求解器决定最佳设置
- 核内存储:通过将所有对象存储在内存中,优化计算时间。
- 评估:在求解器日志中提供最佳设置
- 核外存储:通过在内存外存储对象来优化内存使用
- 特征值求解方法
- IRAM-Sorensen:适用于求解大规模矩阵的特征值分解问题。
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Automatic:求解器根据模型和其他输入自行选择合适的子空间。
- Dimension:直接指定子空间维度。只有在检查错误日志之后才应该这样做,错误日志提供了选择此设置的提示。
- 子空间维度
- Coefficient:用于设置子空间维度与计算频率的数量成比例的乘数。
- 子空间系数
- 精度:定义Sorensen算法迭代停止的判断条件。推荐使用默认值。
- 最大迭代次数:设置求解过程的迭代次数上限。推荐使用默认值。
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Lanczos:适用于求解大规模矩阵的特征值分解问题。通过构建Krylov子空间来近似求解,降低了计算复杂度。特别适用于边界特征值的求解。
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Automatic:求解器根据模型和其他输入自行选择合适的子空间。
- Dimension:直接指定子空间维度。只有在检查错误日志之后才应该这样做,错误日志提供了选择此设置的提示。
- 子空间维度:系统默认为0。
- Coefficient:用于设置子空间维度与计算频率的数量成比例的乘数。
- 子空间系数:系统默认为2。
- 正交精度:正交精度越高,基向量的正交性就越好,这有助于算法的稳定性和准确性。但是,过高的正交精度可能会增加计算成本和复杂度。
- 最大正交迭代次数:限制了Lanczos算法在每次迭代中用于保持基向量正交性的最大迭代次数。当达到这个限制时,算法可能会停止进一步的正交化过程,即使正交精度尚未达到预定的标准。这个参数的选择需要在算法的稳定性和效率之间做出权衡。
- 兰索斯精度:兰索斯精度是指Lanczos算法在逼近大型矩阵的特征值和特征向量时,所达到的精度水平。这个精度水平直接影响到算法的准确性,以及最终计算出的特征值和特征向量的可靠性。提高兰索斯精度可能会增加计算成本,但也会提高解的准确性。
- 最大QR迭代次数:通常用于保持基向量的正交性。这个参数的选择需要考虑到算法的效率和稳定性。如果QR迭代次数过少,可能会导致基向量的正交性丧失;如果过多,则可能会增加计算成本。
- 刚体模态检测:通过刚体模态检测,算法可以确保计算结果的准确性和可靠性,特别是在处理大型和复杂的系统时。
- yes:检测
- no :不检测
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Bathe-Wilson:适用于处理复杂结构或系统的动力学问题,可能提供稳定的数值解。
- 巴特精度:在迭代过程中,算法会检查解的变化是否小于这个设定的精度值。如果是,则认为解已经收敛,迭代可以停止。
- 最大巴特迭代次数:定义了Bathe算法允许的最大迭代次数。即使没有达到设定的精度,如果迭代次数超过了这个值,算法也会停止,并可能报告一个未收敛的警告或错误。
- 雅可比精度:用于确定何时需要更新雅可比矩阵。
- 最大雅可比迭代次数:限制了内部迭代过程的最大次数,以防止它们在无法收敛的情况下无限期地运行。
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Automatic:求解器根据模型和其他输入自行选择合适的子空间。
- Dimension:直接指定子空间维度。只有在检查错误日志之后才应该这样做,错误日志提供了选择此设置的提示。
- 子空间维度:系统默认为0。
- Coefficient:用于设置子空间维度与计算频率的数量成比例的乘数。
- 子空间系数:系统默认为2。
- QZ:适用于求解广义特征值问题;具有良好的数值稳定性和准确性;广泛应用于多个领域。
- 类型:分别代表QZ算法的三种计算方法。
- Simple
- Equi
- QR
- 类型:分别代表QZ算法的三种计算方法。
- IRAM-Sorensen:适用于求解大规模矩阵的特征值分解问题。
- 转换精度:计算过程中涉及变换的精度。
- 最大迭代次数:算法在达到最大迭代次数之前未能收敛到足够的精度,它可能会停止并返回一个警告或错误信息。
- 归一化阈值:用于确定何时特征向量被视为已足够接近单位长度,从而可以被认为是归一化的。
- 核检阈值:用于检查算法稳定性和收敛性的阈值。
- 转换精度:计算过程中涉及变换的精度。
- 提取模态阶数:由用户自定义一个整数,用于限定提取模态的数量。
- LDLT
LDLT对系数矩阵执行经典的高斯消去过程- 奇异性检测精度:设置矩阵奇异性评估的数值精度,如果设置负值则关闭监测
- 特征值求解方法
- IRAM-Sorensen:适用于求解大规模矩阵的特征值分解问题。
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Automatic:求解器根据模型和其他输入自行选择合适的子空间。
- Dimension:直接指定子空间维度。只有在检查错误日志之后才应该这样做,错误日志提供了选择此设置的提示。
- 子空间维度
- Coefficient:用于设置子空间维度与计算频率的数量成比例的乘数。
- 子空间系数
- 精度:定义Sorensen算法迭代停止的判断条件。推荐使用默认值。
- 最大迭代次数:设置求解过程的迭代次数上限。推荐使用默认值。
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Lanczos:适用于求解大规模矩阵的特征值分解问题。通过构建Krylov子空间来近似求解,降低了计算复杂度。特别适用于边界特征值的求解。
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Automatic:求解器根据模型和其他输入自行选择合适的子空间。
- Dimension:直接指定子空间维度。只有在检查错误日志之后才应该这样做,错误日志提供了选择此设置的提示。
- 子空间维度:系统默认为0。
- Coefficient:用于设置子空间维度与计算频率的数量成比例的乘数。
- 子空间系数:系统默认为2。
- 正交精度:正交精度越高,基向量的正交性就越好,这有助于算法的稳定性和准确性。但是,过高的正交精度可能会增加计算成本和复杂度。
- 最大正交迭代次数:限制了Lanczos算法在每次迭代中用于保持基向量正交性的最大迭代次数。当达到这个限制时,算法可能会停止进一步的正交化过程,即使正交精度尚未达到预定的标准。这个参数的选择需要在算法的稳定性和效率之间做出权衡。
- 兰索斯精度:兰索斯精度是指Lanczos算法在逼近大型矩阵的特征值和特征向量时,所达到的精度水平。这个精度水平直接影响到算法的准确性,以及最终计算出的特征值和特征向量的可靠性。提高兰索斯精度可能会增加计算成本,但也会提高解的准确性。
- 最大QR迭代次数:通常用于保持基向量的正交性。这个参数的选择需要考虑到算法的效率和稳定性。如果QR迭代次数过少,可能会导致基向量的正交性丧失;如果过多,则可能会增加计算成本。
- 刚体模态检测:通过刚体模态检测,算法可以确保计算结果的准确性和可靠性,特别是在处理大型和复杂的系统时。
- yes:检测
- no :不检测
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Bathe-Wilson:适用于处理复杂结构或系统的动力学问题,可能提供稳定的数值解。
- 巴特精度:在迭代过程中,算法会检查解的变化是否小于这个设定的精度值。如果是,则认为解已经收敛,迭代可以停止。
- 最大巴特迭代次数:定义了Bathe算法允许的最大迭代次数。即使没有达到设定的精度,如果迭代次数超过了这个值,算法也会停止,并可能报告一个未收敛的警告或错误。
- 雅可比精度:用于确定何时需要更新雅可比矩阵。
- 最大雅可比迭代次数:限制了内部迭代过程的最大次数,以防止它们在无法收敛的情况下无限期地运行。
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Automatic:求解器根据模型和其他输入自行选择合适的子空间。
- Dimension:直接指定子空间维度。只有在检查错误日志之后才应该这样做,错误日志提供了选择此设置的提示。
- 子空间维度:系统默认为0。
- Coefficient:用于设置子空间维度与计算频率的数量成比例的乘数。
- 子空间系数:系统默认为2。
- QZ:适用于求解广义特征值问题;具有良好的数值稳定性和准确性;广泛应用于多个领域。
- 类型:分别代表QZ算法的三种计算方法。
- Simple
- Equi
- QR
- 类型:分别代表QZ算法的三种计算方法。
- IRAM-Sorensen:适用于求解大规模矩阵的特征值分解问题。
- 转换精度:计算过程中涉及变换的精度。
- 最大迭代次数:算法在达到最大迭代次数之前未能收敛到足够的精度,它可能会停止并返回一个警告或错误信息。
- 归一化阈值:用于确定何时特征向量被视为已足够接近单位长度,从而可以被认为是归一化的。
- 核检阈值:用于检查算法稳定性和收敛性的阈值。
- 转换精度:计算过程中涉及变换的精度。
- 提取模态阶数:由用户自定义一个整数,用于限定提取模态的数量。
- MULTIFRONTAL
系数矩阵分解法对矩阵进行LU或Cholesky分解。- 奇异性检测精度:设置矩阵奇异性评估的数值精度,如果设置负值则关闭监测
- 矩阵重新编号方法
- MDA:对超过5000或者更大自由度的大模型选择此选项
- MD:小模型选择此选项
- 特征值求解方法
- IRAM-Sorensen:适用于求解大规模矩阵的特征值分解问题。
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Automatic:求解器根据模型和其他输入自行选择合适的子空间。
- Dimension:直接指定子空间维度。只有在检查错误日志之后才应该这样做,错误日志提供了选择此设置的提示。
- 子空间维度
- Coefficient:用于设置子空间维度与计算频率的数量成比例的乘数。
- 子空间系数
- 精度:定义Sorensen算法迭代停止的判断条件。推荐使用默认值。
- 最大迭代次数:设置求解过程的迭代次数上限。推荐使用默认值。
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Lanczos:适用于求解大规模矩阵的特征值分解问题。通过构建Krylov子空间来近似求解,降低了计算复杂度。特别适用于边界特征值的求解。
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Automatic:求解器根据模型和其他输入自行选择合适的子空间。
- Dimension:直接指定子空间维度。只有在检查错误日志之后才应该这样做,错误日志提供了选择此设置的提示。
- 子空间维度:系统默认为0。
- Coefficient:用于设置子空间维度与计算频率的数量成比例的乘数。
- 子空间系数:系统默认为2。
- 正交精度:正交精度越高,基向量的正交性就越好,这有助于算法的稳定性和准确性。但是,过高的正交精度可能会增加计算成本和复杂度。
- 最大正交迭代次数:限制了Lanczos算法在每次迭代中用于保持基向量正交性的最大迭代次数。当达到这个限制时,算法可能会停止进一步的正交化过程,即使正交精度尚未达到预定的标准。这个参数的选择需要在算法的稳定性和效率之间做出权衡。
- 兰索斯精度:兰索斯精度是指Lanczos算法在逼近大型矩阵的特征值和特征向量时,所达到的精度水平。这个精度水平直接影响到算法的准确性,以及最终计算出的特征值和特征向量的可靠性。提高兰索斯精度可能会增加计算成本,但也会提高解的准确性。
- 最大QR迭代次数:通常用于保持基向量的正交性。这个参数的选择需要考虑到算法的效率和稳定性。如果QR迭代次数过少,可能会导致基向量的正交性丧失;如果过多,则可能会增加计算成本。
- 刚体模态检测:通过刚体模态检测,算法可以确保计算结果的准确性和可靠性,特别是在处理大型和复杂的系统时。
- yes:检测
- no :不检测
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Bathe-Wilson:适用于处理复杂结构或系统的动力学问题,可能提供稳定的数值解。
- 巴特精度:在迭代过程中,算法会检查解的变化是否小于这个设定的精度值。如果是,则认为解已经收敛,迭代可以停止。
- 最大巴特迭代次数:定义了Bathe算法允许的最大迭代次数。即使没有达到设定的精度,如果迭代次数超过了这个值,算法也会停止,并可能报告一个未收敛的警告或错误。
- 雅可比精度:用于确定何时需要更新雅可比矩阵。
- 最大雅可比迭代次数:限制了内部迭代过程的最大次数,以防止它们在无法收敛的情况下无限期地运行。
- 子空间设置:指定特征求解器使用的子空间。只有在解决方案过程中出现建议更改的错误时,才应该更改此设置。一般来说,计算的频率越多,子空间就越大。
- Automatic:求解器根据模型和其他输入自行选择合适的子空间。
- Dimension:直接指定子空间维度。只有在检查错误日志之后才应该这样做,错误日志提供了选择此设置的提示。
- 子空间维度:系统默认为0。
- Coefficient:用于设置子空间维度与计算频率的数量成比例的乘数。
- 子空间系数:系统默认为2。
- QZ:适用于求解广义特征值问题;具有良好的数值稳定性和准确性;广泛应用于多个领域。
- 类型:分别代表QZ算法的三种计算方法。
- Simple
- Equi
- QR
- 类型:分别代表QZ算法的三种计算方法。
- IRAM-Sorensen:适用于求解大规模矩阵的特征值分解问题。
- 转换精度:计算过程中涉及变换的精度。
- 最大迭代次数:算法在达到最大迭代次数之前未能收敛到足够的精度,它可能会停止并返回一个警告或错误信息。
- 归一化阈值:用于确定何时特征向量被视为已足够接近单位长度,从而可以被认为是归一化的。
- 核检阈值:用于检查算法稳定性和收敛性的阈值。
- 转换精度:计算过程中涉及变换的精度。
- 提取模态阶数:由用户自定义一个整数,用于限定提取模态的数量。
3.8.2 响应谱分析设置
该选项卡可设置响应谱激励和模态合成方法,以下会对每种设置及其过程机械阐述;
- 分析类型默认为一致响应谱分析;
- 响应谱类型包含:加速度、速度和位移三种类型;
- 可通过勾选对应方向的选择框来自由选择所需的响应谱方向,并定义该方向的放缩系数,可同时定义多个响应谱和对应的阻尼比,响应谱数据以表格形式输入每阶的频率和幅值,输入完成后可点击数据下载当前定义的响应谱数据表格;
- 由于忽略了高频模态的响应,可能对最终结果产生影响,此时可勾选质量修正使计算结果更加准确;
- 模态合成方法包含:平方根相加法(SRSS)、绝对值相加法(ABS)、完全二次组合法(CQC)、10%法(DPC)、二重和法(DSC)和分组法(GUPTA);
- 方向合成方法包含:平方根求和法(QUAD)和40%法(NEWMARK)。
3.9 时间步&资源
在此选项卡中,用户可设定计算所需的资源和计算时间;
- 计算核数:可定义仿真计算所需的计算核数;
- 最大计算时间:定义仿真的最大时间,超过该值就会自动停止计算。
3.10 结果配置
在此选项卡中,用户可输出响应的结果;
- 物理场:可选择输出结果,包括位移(总位移、周期模态总位移、刚体模态总位移)、应力(总应力、冯米塞斯应力、周期模态总应力、刚体模态总应力);
- 兴趣点结果提取:以列表形式展示之前所选兴趣点的结果。
3.11 仿真计算
用户可在此选项卡中查看仿真计算之后的云图,以及激活的兴趣点的相关结果。